 树链剖分
树链剖分
# 树链剖分
WPY神仙:什么时候能行云流水一次性过树链剖分啊!
树链剖分就是将树分割成多条链,然后利用数据结构(线段树、树状数组等)来维护这些链。别说你不知道什么是树~~ ╮(─▽─)╭
树链剖分有多种形式,如重链剖分,长链剖分和用于 Link/cut Tree 的剖分吗,大多数情况下,树链剖分都指重链剖分
# 重链剖分
# 引入
先来回顾两个问题:
一、将树从 到 结点最短路径上所有节点的值都加上
这也是个模板题了吧
我们很容易想到,树上差分可以以 的优秀复杂度解决这个问题
二、.求树从 到 结点最短路径上所有节点的值之和
LCA 大水题,我们又很容易地想到,DFS 预处理每个节点的 (即到根节点的最短路径长度)
然后对于每个询问,求出 两点的 ,利用 的性质 求出结果
时间复杂度
现在来思考一个结合问题:
如果刚才的两个问题结合起来,成为一道题的两种操作呢?
刚才的方法显然就不够优秀了(每次询问之前要跑 更新 )
树剖是通过轻重边剖分将树分割成多条链,然后利用数据结构来维护这些链(本质上是一种优化暴力)
#
# 明确概念:
- 重儿子:父亲节点的所有儿子中子树结点数目最多( 最大)的结点;
- 轻儿子:父亲节点中除了重儿子以外的儿子;
- 重边:父亲结点和重儿子连成的边;
- 轻边:父亲节点和轻儿子连成的边;
- 重链:由多条重边连接而成的路径;
- 轻链:由多条轻边连接而成的路径;

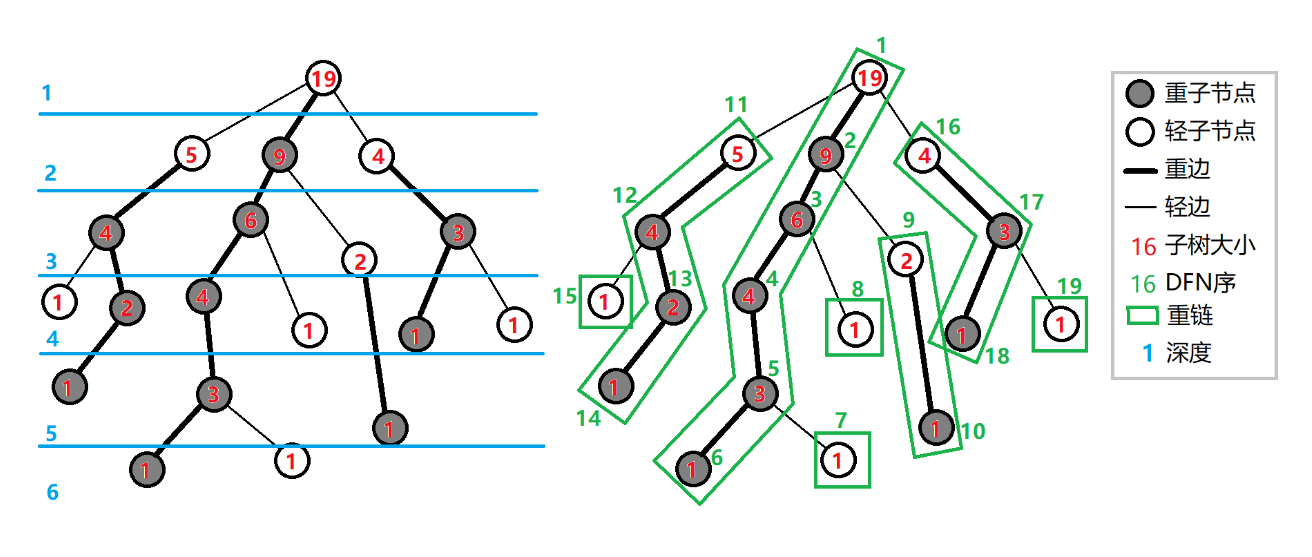
比如上面这幅图中,用黑线连接的结点都是重结点,其余均是轻结点,
就是重链, 就是轻链,用红点标记的就是该结点所在重链的起点,也就是下文提到的 结点,
还有每条边的值其实是进行 时的执行序号。
# 声明变量:
int cnt,lnk[maxn],nxt[maxn<<1],to[maxn<<1];//建边
int a[maxn<<2],lazy[maxn<<2];//线段树
int son[maxn],w[maxn],id[maxn],tot,deep[maxn],size[maxn],top[maxn],fa[maxn],rk[maxn];
/*
son[maxn]:重儿子,
w[maxn]:权值,
id[maxn]:树上节点对应线段树上的标号,
deep[maxn]:节点深度,
size[maxn]节点子树大小,
top[maxn]链最上端的编号,
fa[maxn]父节点,
rk[maxn]线段树上编号对应的树上节点
*/
2
3
4
5
6
7
8
9
10
11
12
13
其中 可以看作是 的逆映射
# 树链剖分的实现
1. 对于一个点我们首先求出它所在的子树大小,找到它的重儿子(即处理出size,son数组
解释:比如说点 ,它有三个儿子 , 所在子树的大小是 , 所在子树的大小是 , 所在子树的大小是 ,那么 的重儿子是
如果一个点的多个儿子所在子树大小相等且最大,那随便找一个当做它的重儿子就好了,叶节点没有重儿子,非叶节点有且只有一个重儿子
2.在dfs过程中顺便记录其父亲以及深度(即处理出 f,d 数组),操作1,2可以通过一遍 完成
void DFS_1(int x,int f,int dep){
deep[x]=dep;fa[x]=f;size[x]=1;
int max_son=-1;
for(int j=lnk[x];j;j=nxt[j]){
if(to[j]==f)continue;
DFS_1(to[j],x,dep+1);
size[x]+=size[to[j]];
if(size[to[j]]>max_son){max_son=size[to[j]],son[x]=to[j];}
}
return ;
}
2
3
4
5
6
7
8
9
10
11

dfs跑完大概是这样的,大家可以手动模拟一下
3.第二遍dfs,然后连接重链,同时标记每一个节点的dfs序,并且为了用数据结构来维护重链,我们在dfs时保证一条重链上各个节点dfs序连续(即处理出数组 , , )
inline void DFS_2(int x,int tp){
id[x]=++tot;
rk[tot]=x;
top[x]=tp;
if(son[x])DFS_2(son[x],tp);
for(int j=lnk[x];j;j=nxt[j]){
if(to[j]==fa[x]||to[j]==son[x])continue;
DFS_2(to[j],to[j]);
}
return ;
}
2
3
4
5
6
7
8
9
10
11

跑完大概是这样的,大家可以手动模拟一下
4.两遍 就是树链剖分的主要处理,通过第二次 我们已经保证一条重链上各个节点 序连续,那么可以想到,我们可以通过数据结构(以线段树为例)来维护一条重链的信息
# 重链剖分的性质
- 树上每个节点都属于且仅属于一条重链
- 在剖分时 重边优先遍历,最后树的 DFS 序上,重链内的 DFS 序是连续的。按 DFN 排序后的序列即为剖分后的链
- 一颗子树内的 DFS 序是连续的
- 可以发现,当我们向下经过一条轻边 时,所在子树的大小至少会除以二,因此,对于树上的任意一条路径,把它拆分成从 分别向两边往下走,分别最多走 次,着等价于树上的每条路径都可以被拆分成不超过 条重链
# 应用
# 树上路径维护
由于重链内的 DFS 序是连续的,我们把一条链的两个端点 ,分别沿着重链向上面跳,直到跳到 ,在跳的同时维护重链上的信息
例如,用树链剖分求树上两点路径权值和的伪代码如下:

每次选择深度较大的链往上跳,直到两点在同一条链上
同样的跳链结构适用于维护、统计路径上的其他信息
# 子树维护
# 求最近公共祖先
不断向上跳重链,当跳到同一条重链上时,深度较小的结点即为 LCA
向上跳重链时需要先跳所在重链顶端深度较大的那个
# 复杂度
树链剖分的两个性质:
1,如果 是一条轻边,那么;
2,从根结点到任意结点的路所经过的轻重链的个数必定都小于;
可以证明,树链剖分的时间复杂度为
#include<bits/stdc++.h>
using namespace std;
const int maxn=100005;
typedef long long LL;
int N,M,R,TT;
int ret;
inline int read(){
int ret=0,f=1;char ch=getchar();
while(ch<'0'|ch>'9'){if(ch=='-')f=-f;ch=getchar();}
while(ch<='9'&&ch>='0')ret=ret*10+ch-'0',ch=getchar();
return ret*f;
}
int cnt,lnk[maxn],nxt[maxn<<1],to[maxn<<1],w[maxn];
int a[maxn<<2],lazy[maxn<<2];
int son[maxn],id[maxn],tot,deep[maxn],size[maxn],top[maxn],fa[maxn],rk[maxn];
inline void add_e(int x,int y){to[++cnt]=y;nxt[cnt]=lnk[x];lnk[x]=cnt;}
inline void DFS_1(int x,int f,int dep){
deep[x]=dep;fa[x]=f;size[x]=1;
int max_son=-1;
for(int j=lnk[x];j;j=nxt[j]){
if(to[j]==f)continue;
DFS_1(to[j],x,dep+1);
size[x]+=size[to[j]];
if(size[to[j]]>max_son){max_son=size[to[j]],son[x]=to[j];}
}
return ;
}
inline void DFS_2(int x,int tp){
id[x]=++tot;
rk[tot]=x;
top[x]=tp;
if(son[x])DFS_2(son[x],tp);
for(int j=lnk[x];j;j=nxt[j]){
if(to[j]==fa[x]||to[j]==son[x])continue;
DFS_2(to[j],to[j]);
}
return ;
}
inline void build(int x,int L,int R){
if(L==R){
a[x]=w[rk[L]]%TT;
return ;
}
int mid=(R-L>>1)+L;
build(x<<1,L,mid);
build(x<<1|1,mid+1,R);
a[x]=(a[x<<1]+a[x<<1|1])%TT;
return ;
}
inline void pushdown(int x,int len){
if(lazy[x]==0)return ;
lazy[x<<1]=(lazy[x<<1]+lazy[x])%TT;
lazy[x<<1|1]=(lazy[x<<1|1]+lazy[x])%TT;
a[x<<1]=(a[x<<1]+lazy[x]*(len-(len>>1)))%TT;
a[x<<1|1]=(a[x<<1|1]+lazy[x]*(len>>1))%TT;
lazy[x]=0;
return ;
}
inline void query(int x,int l,int r,int L,int R){
if(L<=l&&r<=R){ret=(ret+a[x])%TT;return ;}
else {
pushdown(x,r-l+1);int mid=(r-l>>1)+l;
if(L<=mid)query(x<<1,l,mid,L,R);
if(R>mid)query(x<<1|1,mid+1,r,L,R);
}
return ;
}
inline void update(int x,int l,int r,int L,int R,int k){
if(L<=l&&r<=R){
lazy[x]=(lazy[x]+k)%TT;
a[x]=(a[x]+k*(r-l+1))%TT;
}
else{
pushdown(x,r-l+1);
int mid=(r-l>>1)+l;
if(L<=mid)update(x<<1,l,mid,L,R,k);
if(R>mid)update(x<<1|1,mid+1,r,L,R,k);
a[x]=(a[x<<1]+a[x<<1|1])%TT;
}
return ;
}
inline int qRange(int x,int y){
int ans=0;
while(top[x]!=top[y]){
if(deep[top[x]]<deep[top[y]])swap(x,y);
ret=0;
query(1,1,N,id[top[x]],id[x]);
ans=(ret+ans)%TT;
x=fa[top[x]];
}
if(deep[x]>deep[y])swap(x,y);
ret=0;query(1,1,N,id[x],id[y]);
ans=(ans+ret)%TT;
return ans;
}
inline void upRange(int x,int y,int k){
k%=TT;
while(top[x]!=top[y]){
if(deep[top[x]]<deep[top[y]])swap(x,y);
update(1,1,N,id[top[x]],id[x],k);
x=fa[top[x]];
}
if(deep[x]>deep[y])swap(x,y);
update(1,1,N,id[x],id[y],k);
return ;
}
inline int qson(int x){
ret=0;
query(1,1,N,id[x],id[x]+size[x]-1);
return ret;
}
inline void upson(int x,int k){
update(1,1,N,id[x],id[x]+size[x]-1,k);
}
int main(){
N=read();M=read();R=read();TT=read();
for(int i=1;i<=N;i++)w[i]=read();
for(int i=1;i<N;i++){
int x=read(),y=read();
add_e(x,y);add_e(y,x);
}
DFS_1(R,0,1);
DFS_2(R,R);
build(1,1,N);
for(int i=1;i<=M;i++){
int p,x,y,k;
p=read();
if(p==1){x=read(),y=read(),k=read();upRange(x,y,k);}
if(p==2){x=read();y=read();printf("%d\n",qRange(x,y));}
if(p==3){x=read();k=read();upson(x,k);}
if(p==4){x=read();printf("%d\n",qson(x));}
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
单点修改,区间查询代码
int n;
struct node{
int son,w,id,dep,siz,top,fa;
vector<int> E;
};
vector<node> c;
int tot;
vector<int> rk;
struct SegTree{
int n;
vector<int> sum,max_x;
void init(int n){
this->n=n;
sum.resize(n*4);max_x.resize(n*4);
}
void build(int x,int l,int r){
if(l==r) {
sum[x]=max_x[x]=c[rk[l]].w;
return ;
}
int mid=(l+r)>>1;
build(x<<1,l,mid);
build(x<<1|1,mid+1,r);
sum[x]=sum[x<<1]+sum[x<<1|1];
max_x[x]=max(max_x[x<<1],max_x[x<<1|1]);
}
int query_max(int x,int l,int r,int ql,int qr){
if(l>qr||r<ql) return -INF;
if(ql<=l&&r<=qr) return max_x[x];
int mid=(l+r)>>1;
return max(query_max(x<<1,l,mid,ql,qr),query_max(x<<1|1,mid+1,r,ql,qr));
}
int query_sum(int x,int l,int r,int ql,int qr){
if(l>qr||r<ql) return 0;
if(ql<=l&&r<=qr) return sum[x];
int mid=(l+r)>>1;
return query_sum(x<<1,l,mid,ql,qr)+query_sum(x<<1|1,mid+1,r,ql,qr);
}
void update(int x,int l,int r,int pos,int val){
if(l==r){max_x[x]=sum[x]=val;return ;};
int mid=(l+r)>>1;
if(pos<=mid)
update(x<<1,l,mid,pos,val);
else
update(x<<1|1,mid+1,r,pos,val);
sum[x]=sum[x<<1]+sum[x<<1|1];
max_x[x]=max(max_x[x<<1],max_x[x<<1|1]);
}
}st;
void add_e(int x,int y){
c[x].E.push_back(y);
}
void dfs_1(int u,int f,int dp){
c[u].dep=dp;c[u].fa=f;c[u].siz=1;
int max_son=-1;
for(auto& v:c[u].E){
if(v==c[u].fa) continue;
dfs_1(v,u,dp+1);
c[u].siz+=c[v].siz;
if(c[v].siz>max_son){max_son=c[v].siz,c[u].son=v;}
}
}
void dfs_2(int u,int tp){
c[u].id=++tot;rk[tot]=u;c[u].top=tp;
if(c[u].son) dfs_2(c[u].son,tp);
for(auto& v:c[u].E){
if(v==c[u].fa||v==c[u].son) continue;
dfs_2(v,v);
}
}
int tree_query_max(int x,int y){
int ret=-INF,fx=c[x].top,fy=c[y].top;
while(fx!=fy){
if(c[fx].dep>=c[fy].dep)
ret=max(ret,st.query_max(1,1,n,c[fx].id,c[x].id)),x=c[fx].fa;
else
ret=max(ret,st.query_max(1,1,n,c[fy].id,c[y].id)),y=c[fy].fa;
fx=c[x].top;fy=c[y].top;
}
if(c[x].id<c[y].id) //最后那条链上的一段
ret=max(ret,st.query_max(1,1,n,c[x].id,c[y].id));
else
ret=max(ret,st.query_max(1,1,n,c[y].id,c[x].id));
return ret;
}
int tree_query_sum(int x,int y){
int ret=0,fx=c[x].top,fy=c[y].top;
while(fx!=fy){
if(c[fx].dep>=c[fy].dep)
ret+=st.query_sum(1,1,n,c[fx].id,c[x].id),x=c[fx].fa;
else
ret+=st.query_sum(1,1,n,c[fy].id,c[y].id),y=c[fy].fa;
fx=c[x].top;fy=c[y].top;
}
if(c[x].id<c[y].id)
ret+=st.query_sum(1,1,n,c[x].id,c[y].id);
else
ret+=st.query_sum(1,1,n,c[y].id,c[x].id);
return ret;
}
void init(int n){
c.resize(n+1);
rk.resize(n+1);
st.init(n);
}
int main(){
freopen("P2590.in","r",stdin);
freopen("P2590.out","w",stdout);
n=read();int u=0,v=0;
init(n);
for(int i=1;i<n;i++){
int x=read(),y=read();
add_e(x,y);add_e(y,x);
}
for(int i=1;i<=n;i++)
c[i].w=read();
dfs_1(1,-1,1);
dfs_2(1,1);
st.build(1,1,n);
int Q=read();
while(Q--){
string s;
cin>>s;u=read(),v=read();
if(s=="CHANGE")
st.update(1,1,n,c[u].id,v);
if(s=="QMAX")
printf("%d\n",tree_query_max(u,v));
if(s=="QSUM")
printf("%d\n",tree_query_sum(u,v));
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
WPY神仙:什么时候能行云流水一次性过树链剖分啊!
前后呼应
# 长链剖分
长链剖分本质上就是另外一种链剖方式
定义 重子节点 表示其子节点重深度最大的子节点。如果有多个子树最大的子节点,取其一,如果没有子节点,就无重子节点
定义轻子节点表示剩余的子节点
从这个结点到重子节点的边为 重边,
其他轻子节点的边为 轻边
若干条首位衔接的重边构成 重链
把落单的结点也当作重链,那么整棵树就被剖分成若干条重链
# 性质
长链剖分从一个结点到根的路径的轻边切换条数是 级别的