 机器学习笔记
机器学习笔记
# 机器学习笔记
# 前言
# 监督学习
回归问题
有监督学习中,你的训练集存在一个输入数据 和一个正确的答案 ,算法根据训练集训练,然后给出一个位置的 来预测一个新的
这里我们根据 ,从无数个数中预测
分类问题
上面的回归问题是从无数的数中预测一个 ,分类问题是根据训练数据训练算法,然后对于一个新的 ,把这个 分到规定的几类中
例如:根据肿瘤的大小来判断肿瘤是恶性的还是良性的
# 无监督学习
无监督学习对于数据 不会给出对应的正确输出 ,需要程序自己去发现数据中一些特殊的结构或者规律
聚类算法
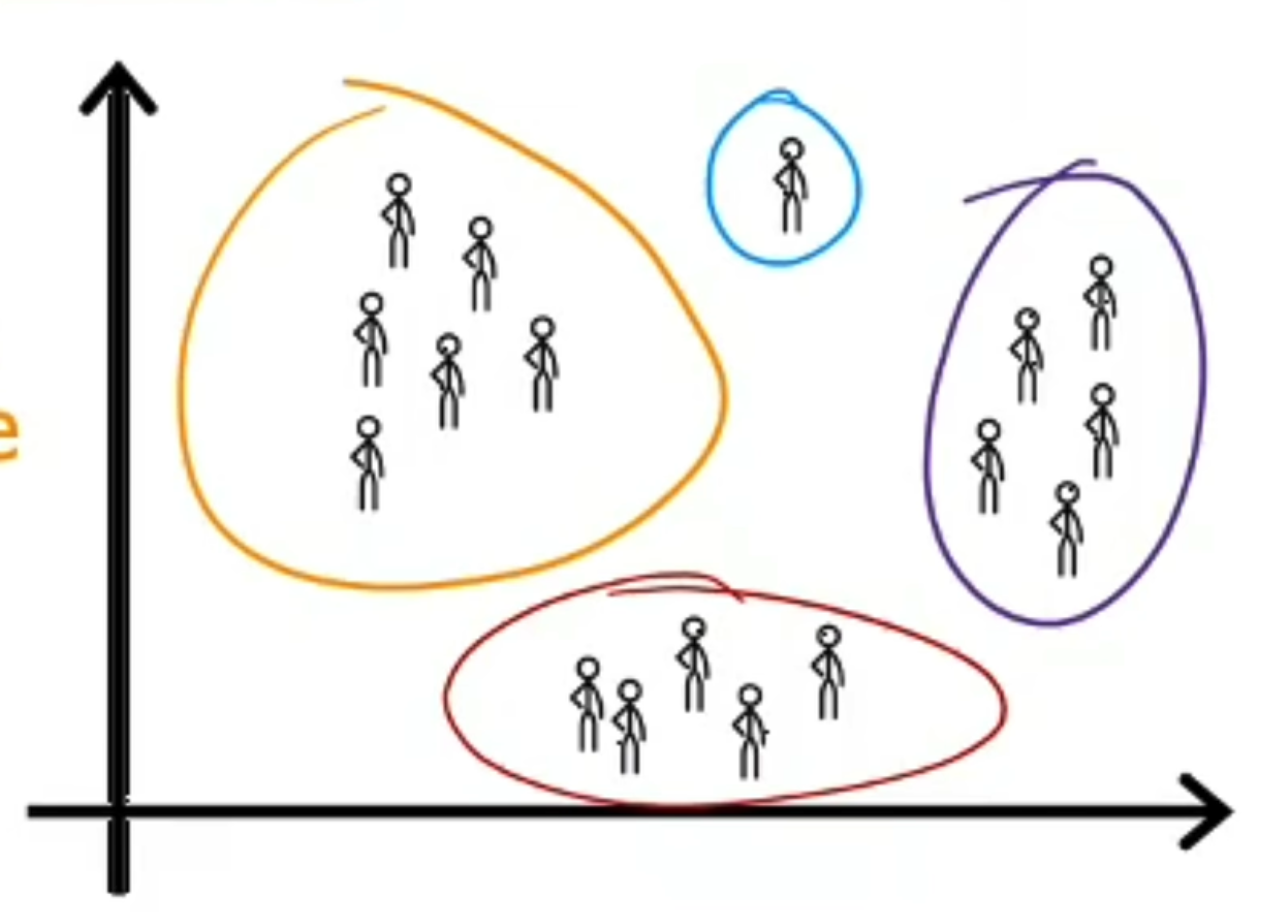
在图中,我们可以发现一类人有相似的一些特征,所以我们把他们归为一类
Anomaly detection
异常值检测
# 线性回归
# 一元线性回归
观察一条直线,,我们给定一个 就能得到一个
当我们用一个 来预测 ,就是一元线性回归模型
我们现在有一堆数据集 ,然后我需要找到合适的 来拟合这些点
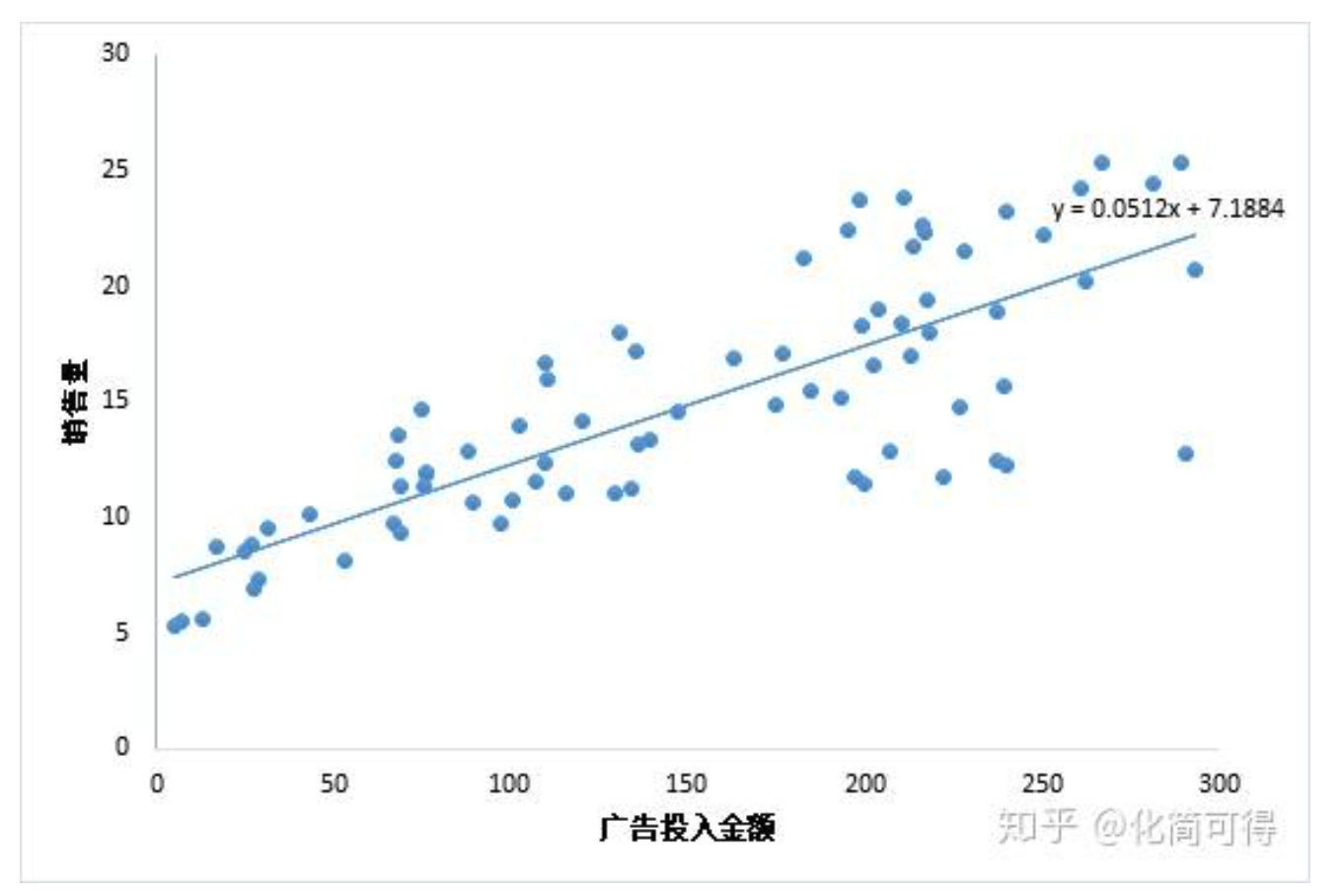
于是,当来了一个新的 ,就能得到一个 了
我们需要一个评价标准来评判一条直线的拟合程度,于是就有了损失函数
定义真实值和预测值之间的差值为残差:
那么误差就是残差平方和,叫 损失函数
我们的目标就是需要找到最小化 ,即:
求解 和 使得 被称为最小二乘估计,对 分别求偏导数,得到:
两个偏导数等于 就可以得到 和 对最优解
其中 为 的均值
# 多元线性回归
给定数据集 ,其中 ,这里的 是一个向量的形式,我们试图得到一个矩阵
类似的,我们可以用最小二乘法来对 和 进行估计,我们把 写成一个 ,把数据集表示成一个 大小大矩阵 ,其中每一行对应一个示例,最后一个元素恒为 $$ \mathbf{X}=\left(\begin{array}{ccccc} x_{11} & x_{12} & \ldots & x_{1 d} & 1 \ x_{21} & x_{22} & \ldots & x_{2 d} & 1 \ \vdots & \vdots & \ddots & \vdots & \vdots \ x_{m 1} & x_{m 2} & \ldots & x_{m d} & 1 \end{array}\right)=\left(\begin{array}{cc} \boldsymbol{x}{1}^{\mathrm{T}} & 1 \ \boldsymbol{x}{2}^{\mathrm{T}} & 1 \ \vdots & \vdots \ \boldsymbol{x}_{m}^{\mathrm{T}} & 1 \end{array}\right) $$
把标记也写成向量形式 ,那么多位的损失函数就可以写成:
令 ,对 求导得到
当 为满秩矩阵或正定矩阵时
令 可得,多元线性回归模型为
# 使用梯度下降求解多元线性回归
考虑单变量的线性回归中,我们考虑每次迭代 和 ,方程如下 $$ \begin{aligned} w&=w-\alpha \frac{\partial}{\partial w} J(w,b)=w-\alpha \frac{1}{m}\sum_{i=1}^m(f_{w,b}(x^{(i)})-y^{(i)})x^{i}\ b&=b-\alpha \frac{\partial}{\partial b} J(w,b)=b-\alpha \frac{1}{m}\sum_{i=1}^m(f_{w,b}(x^{(i)})-y^{(i)}) \end{aligned} $$ 在多元线性回归中, 和 都是一个向量,所以,上面那个方程需要做一些改变 $$ \begin{aligned} w_1&=w_1-\alpha \frac{\partial}{\partial w} J(w,b)=w_1-\alpha \frac{1}{m}\sum_{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})x^{i}1\ \cdots\ w_n&=w_n-\alpha \frac{\partial}{\partial w} J(w,b)=w_n-\alpha \frac{1}{m}\sum{i=1}^m(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})x^{i}n\ b&=b-\alpha \frac{\partial}{\partial b} J(w,b)=b-\alpha \frac{1}{m}\sum{i=1}^m(f_{w,b}(x^{(i)})-y^{(i)}) \end{aligned} $$
# 梯度下降
假设你有一个代价函数 ,你需要找到
基本算法思想是:
- 给 一个初始,通常是
- 稍微改变一点 来减少
- 直到 稳定在最小值附近
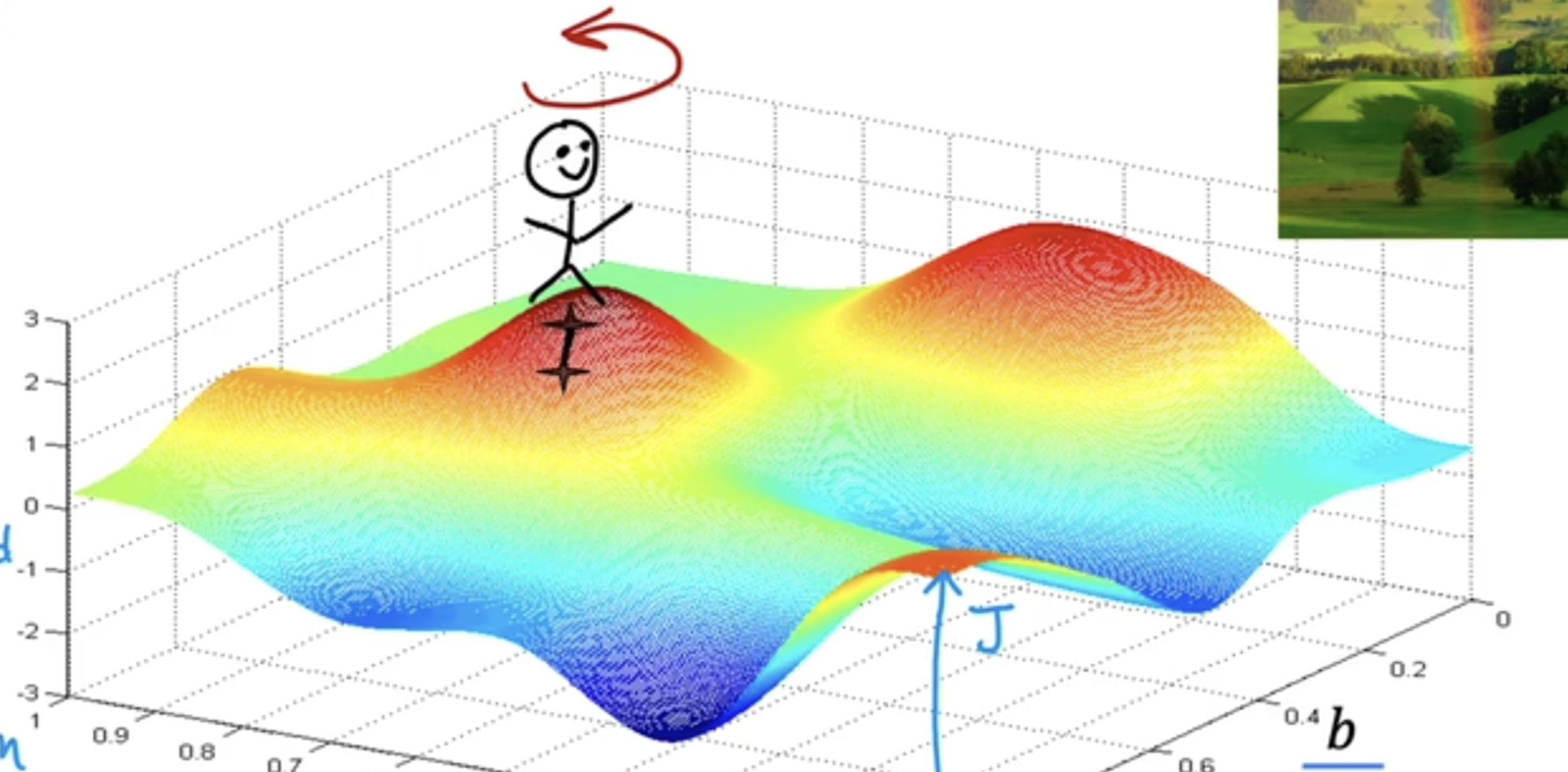
假设你站在这个山顶上,你要往前试探性的走一步,然后看往那个方向走能让你更快得降到山谷中,然后就往那个方向走一步,以此类推
接下来我们来看一下如何具体实现梯度下降算法,这里实现了 的同时更新 $$ \begin{aligned} w&=w-\alpha \frac{\partial}{\partial w} J(w,b)\ b&=b-\alpha \frac{\partial}{\partial b} J(w,b) \end{aligned} $$
- 这里的 是学习率,其决定了梯度下降的步伐大小
如果学习率 特别小,梯度下降算法会起作用,但是需要很长的时间
如果学习率 太大,梯度下降算法可能无法找到最小值
# 检查梯度下降是否收敛
我们将梯度下降的次数为横轴, 为纵轴,花了一个图
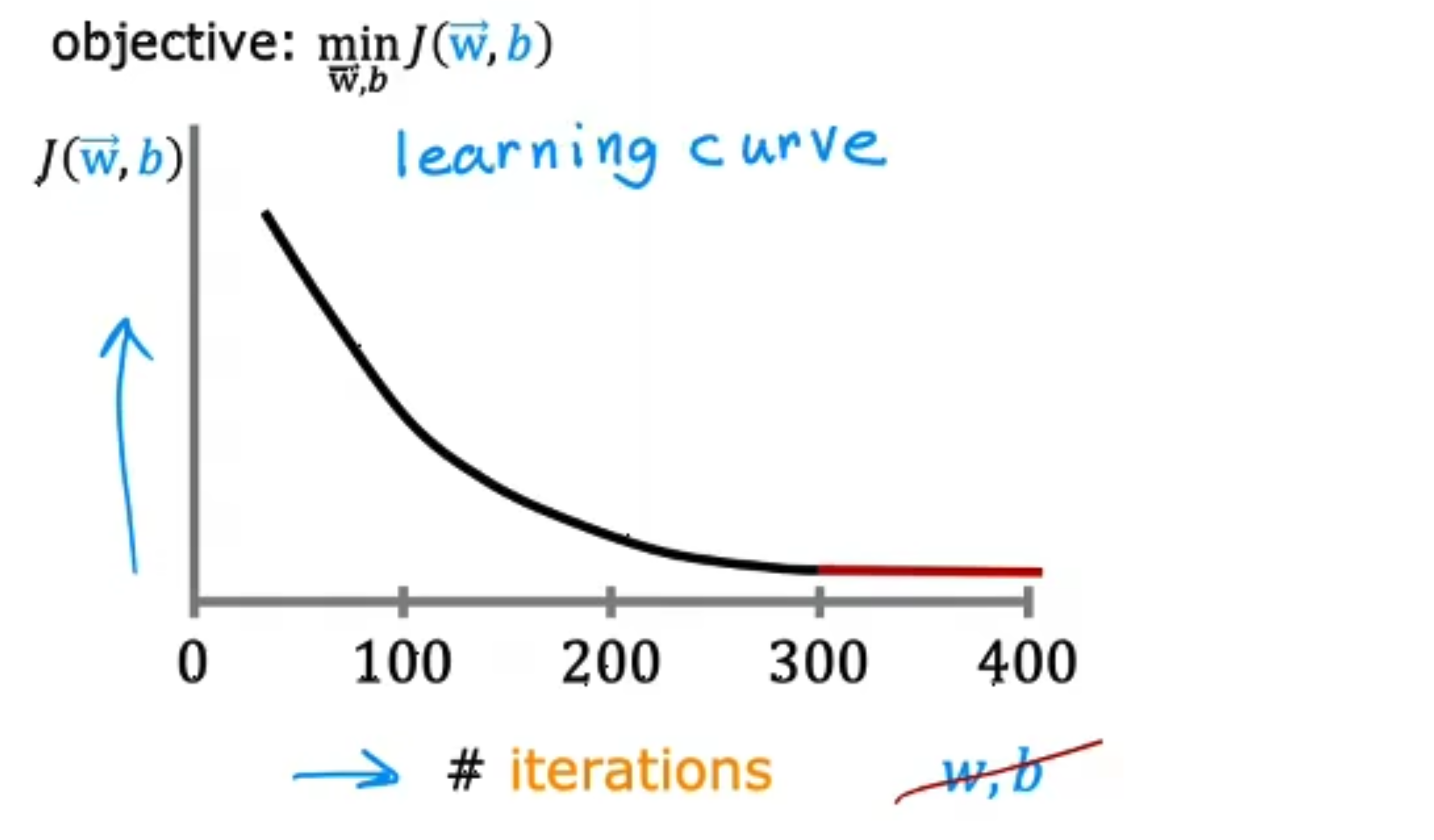
从这个图中可以看到,整个曲线呈一个下降的趋势,如果有一段不下降反而上升了,说明有可能 取得太大了,或者程序编写错误了
如果最后的图变得很平缓,说明梯度下降收敛了
我们可以先使用一个较小的 来看梯度下降是否收敛,然后慢慢调大,例如,可以从 开始,每次扩大 10 倍这样子
# 特征工程
例如我们要估算一个房子的价格,首先我们可以选择房子的长度和宽度作为参数

这样我们的函数就是
当然,我们同样可以令 ,于是我们得到的函数可以是
特征工程指的就是你基于对事物的理解来选取合适的特征
# 逻辑回归
我们在使用了线性回归之后,还可以使用一个逻辑函数 来优化回归过程,也就是我们讲的逻辑回归
于是,逻辑回归的柿子就变成了 $$ f(x)=g(z)=\frac{1}{1+e^{-(wx+b)}} $$ 如果我们面临一个二分类问题,即非 即 那么我们可以设置一个值 当预测的参数小于 的时候被认为是 ,否则被认为是